I was lazy and used a pickle file as database, then the obvious thing happened and it blew up. Since it was supposed to be a temporary quick-and-dirty solution, there was no backup even though the script had ended up running and collecting data on a small VPS for multiple days before breaking. Unfortunately, there was no way to re-capture the past live data forcing me to attempt rescue from the corrupted pickle file. When trying to load the corrupted file, we get one of the following errors:
|
|
The goal is to quickly fix the file so that it can be unpickled again, recovering the uncorrupted part of the data.
The pickle format
Why it breaks
Pickle is convenient because it allows dumping and restoring entire python objects. It’s not suitable as a database format because it requires reading and writing the whole object to/from the file every time.
In my case, the data dumped from a web API had quickly grown to a couple GB over a few days which meant the pickled object became too large for the VPS’ RAM and at some point, the python process was killed due to memory exhaustion. Unfortunately, this happened after the pickle file had been opened for writing (wb) which means the old content was already gone. Fortunately, it happened somewhere during the writing of the new pickled data, so that most of the data was dumped back into the file, although truncated at the point where the process was killed.
If the pickle file was corrupted by truncation, the recoverable data is whatever is at the start of the file. If data is stored row-wise or list-like, you’ll recover the first N rows. Pandas tends to store data in column wise format, in which case you’ll likely recover the first N columns. However, if only a small part of the file at the end is missing, you’ll be able to recover most of the data either way.
Inner workings
Pickle is a binary serialization protocol that converts object hierarchies into byte streams using stack-based operations. Basically, the unpickler executes a series of opcodes in the pickle file thereby reconstructing objects by pushing and popping items on a stack. This means that containers like lists or dicts are essentially constructed “in order”, similarly to how they would in a json file, which is great in our case because it means that the objects in the beginning of the file aren’t affected by the end being cut off.
The available opcodes in the pickle VM are listed in the respective file in the python module. Additionally, you can use pickletools to generate a disassembly of the pickle file, making it much easier to read. However, this will not (practically) work for huge files. The pickletools.py also has some more extensive documentation about the opcodes and internals of the pickle VM.
For our purposes, there are really only a few opcodes that need to be understood to be able to patch up the broken file. I’ll show the relevant aspects of the file format in an example:
|
|
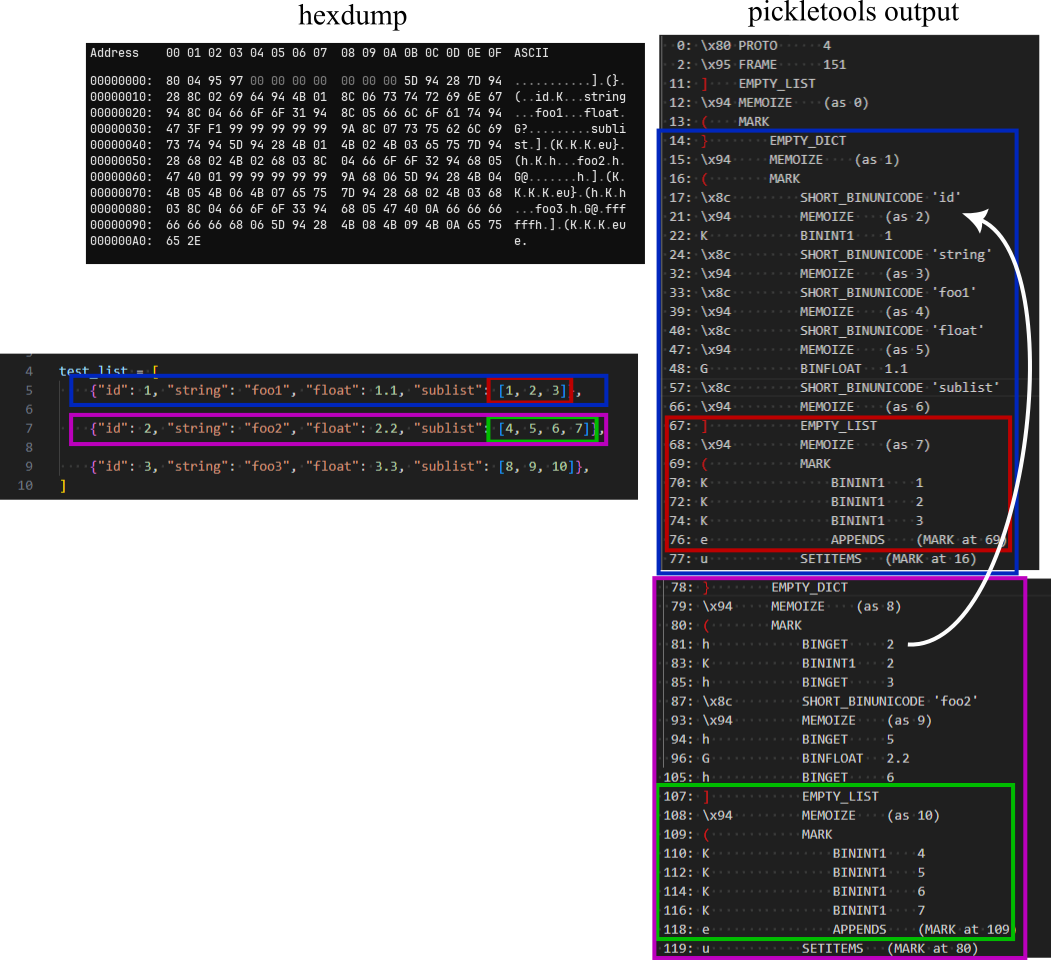
The image below disects the binary representations of the first and second elements in the list. The first element is actually pretty easy to read in the pickletools output (and even the hex dump) because the dict’s keys are spelled out in plain text. Essentially, the dict is “opened” with EMPTY_DICT (opcode is 0x7d or ‘}’ in ASCII), then keys and values are pushed onto the stack alternatingly, before SETITEMS collects all of the key-value pairs and puts them into the dict. The nested list works very similar, starting with EMPTY_LIST (ASCII ‘]’), then pushing each element before adding them all to the list with APPENDS.
Both SETITEMS and APPENDS add the topmost items from the stack to the dict/list stopping at the first MARK object on the stack. This is why a series of elements is always preceded with an MARK opcode and printed with the respective indent in the pickletools output.
The second dict in the list is missing the key strings, which makes it more difficult to read, especially in the hexdump. Since the dicts all have the same keys, it would be quite inefficient to recreate all of them from the binary string each time they are used. This is why they are saved to a memo (MEMOIZE) after creation and are then loaded from the memo (basically a parallel data structure to the stack, similar to registers) by referring to an incremented ID using the BINGET opcode. This is convenient for the binary representation but makes it more difficult to read in later instances.
Luckily, dicts also cover the creation of custom objects. These are built by creating their __dict__ as described above, and then applying the BUILD opcode.
Fixing the file
From understanding the pickle format, it’s also easy to understand how a corrupted file can be fixed. Obviously, if the file is truncated at a random position, the hierarchical object creation operations are cut off somewhere in the middle, leaving an invalid state. The goal is to find the last intact object in the binary, remove the broken rest behind it, and tie the file off correctly.
As an example file to fix, I will use a couple hundred MB of OHLC crypto data from binance. This data is a very long list of dicts like this:
|
|
Step 1: Remove broken objects and tie off the file
The first step is figuring the file boundary, i.e. what opcodes are necessary after the last payload element to create the pickled object. This pickled object is likely going to be a dict (final assembly via SETITEMS), a list (final assembly via APPENDS) or a custom object (final assembly via SETITEMS to create __dict__, then BUILD to create the object). The easiest way to definitively figure this out is by just pickling a file with mockup data and taking a look at the hexdump.
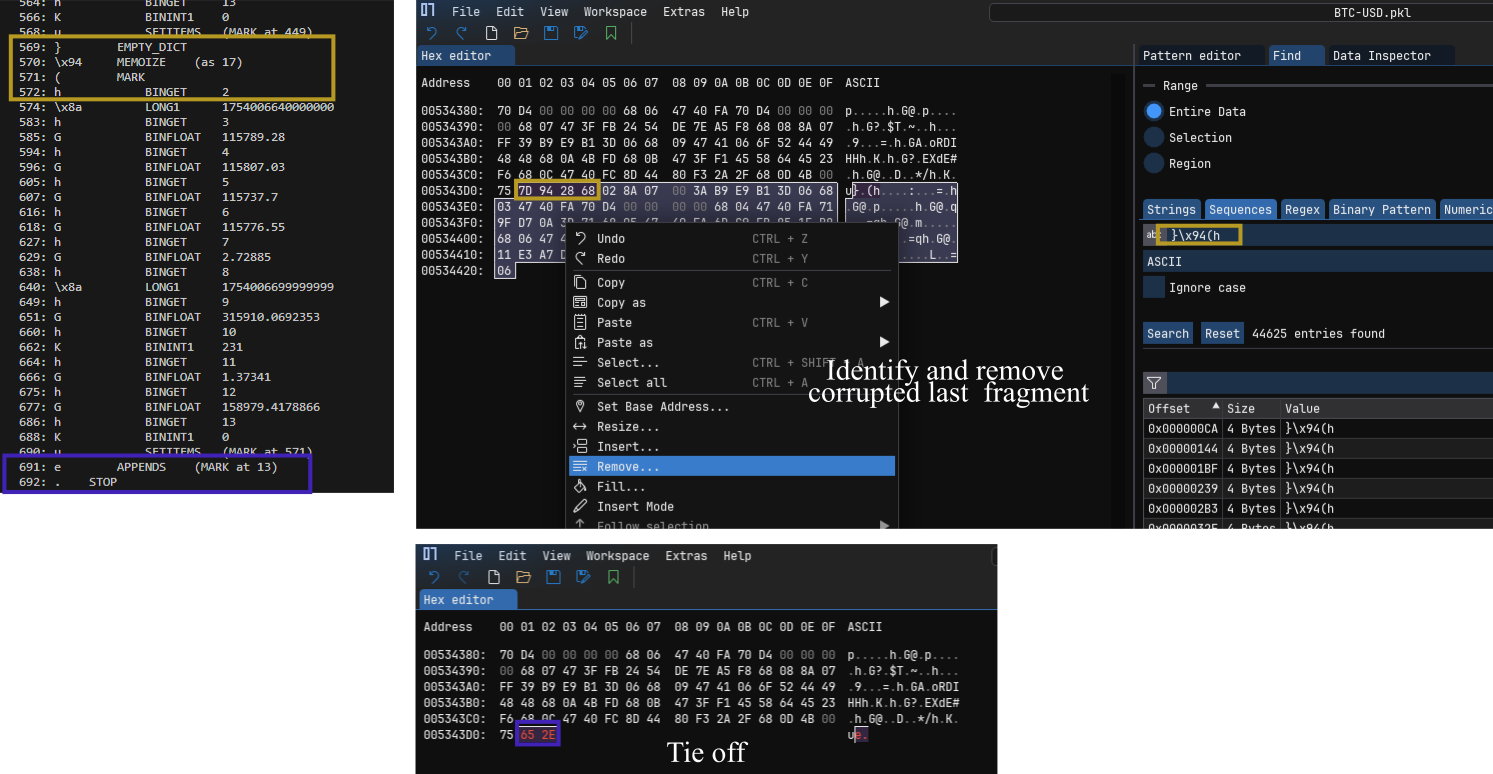
In our example case, we’re building a list of dicts, and the image below shows on the left side how this data structure is tied off in an uncorrupted file: The last dict is assembled with SETITEMS, then a number of such dicts on the stack are appended to the long list with APPENDS and the final opcode terminating the file is STOP.
On the right side of the image, we can see the end of the corrupted file. You can tell it’s corrupted from a first glance because it ends in an 0x06 instead of in 0x2e (STOP opcode, ASCII .). We then find the start of the last (corrupted) dict by searching for the first bytes starting each new dict (beginning with EMPTY_DICT), then remove the remnants of the last dict and tie off the file by adding all remaining dicts on the stack to the list (APPENDS = 0x65, ASCII e) and then terminating the file (STOP = 0x2e, ASCII .).
However, this doesn’t make the file unpickleable again, we have to fix one more thing.
Step 2: Fix frame
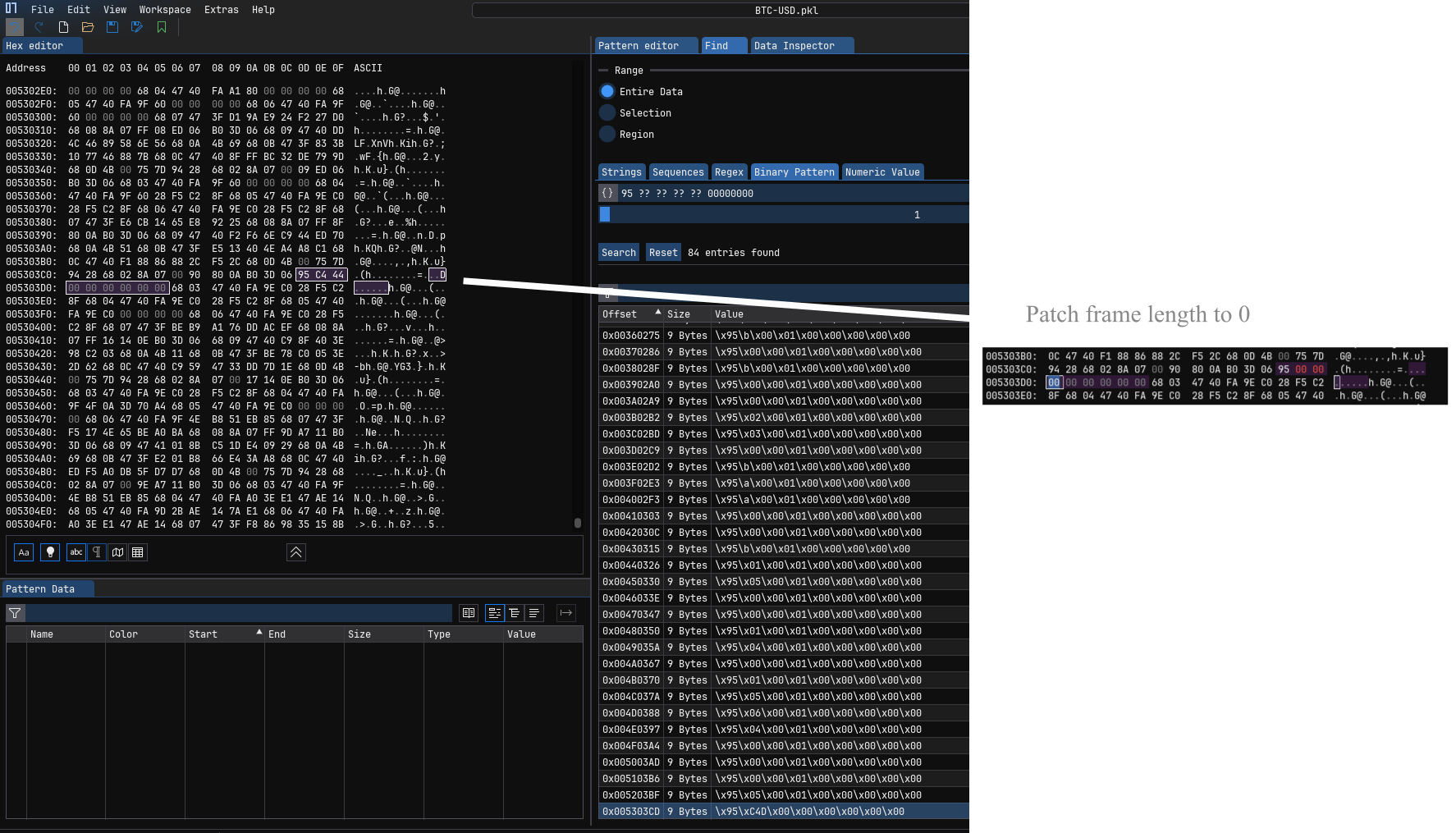
The FRAME opcode (0x95) comes with an 8-byte unsigned integer argument specifying the length of a new frame starting in the file. This allows the unpickler to prefetch the given number of bytes safely. When a file is truncated and after we have cut off all broken objects in the end of the file, the last frame is likely incomplete.
We therefore have to find the last FRAME opcode and fix the length of the frame. I’m using the search function of to find them by using a pattern like
0x95 ?? ?? ?? ?? 00 00 00 00 assuming that the little endian frame length will never be larger than a 32 bit integer (actually it seems to be below 2^16 in the pickle implementations I’ve seen). Using a pattern like this will reduce the number of false positives compared to just searching for 0x95. I then patch the frame length of the last frame to 0 for simplicity, disabling prefetching for the last frame. Alternatively, you could figure out the correct new frame length and put it in, but this is error prone and not necessary, since the prefetching is only for performance reasons.
With these patches, the file can be unpickled correctly again.
Pickle alternatives for a database
So what would be a suitable alternative to pickle for a simple datalogging application where a “real” database would be overkill and performance is not so relevant?
I’ve come to like JSON Lines which is exactly what it sounds like, i.e. you append each object or row in your “database” serialized into a line of json to a file (e.g. .jsonl). Just like pickle, the (de)serialization facilities for json come with python, making it a low effort solution. Importantly, the file can be read and written line by line without the need to keep the entire file in memory.